
IMDb Dataset
The IMDb dataset is a comprehensive collection of information about movies, TV shows, and the entertainment industry. It includes metadata such as titles, genres, release dates, ratings, cast and crew details, and user reviews.
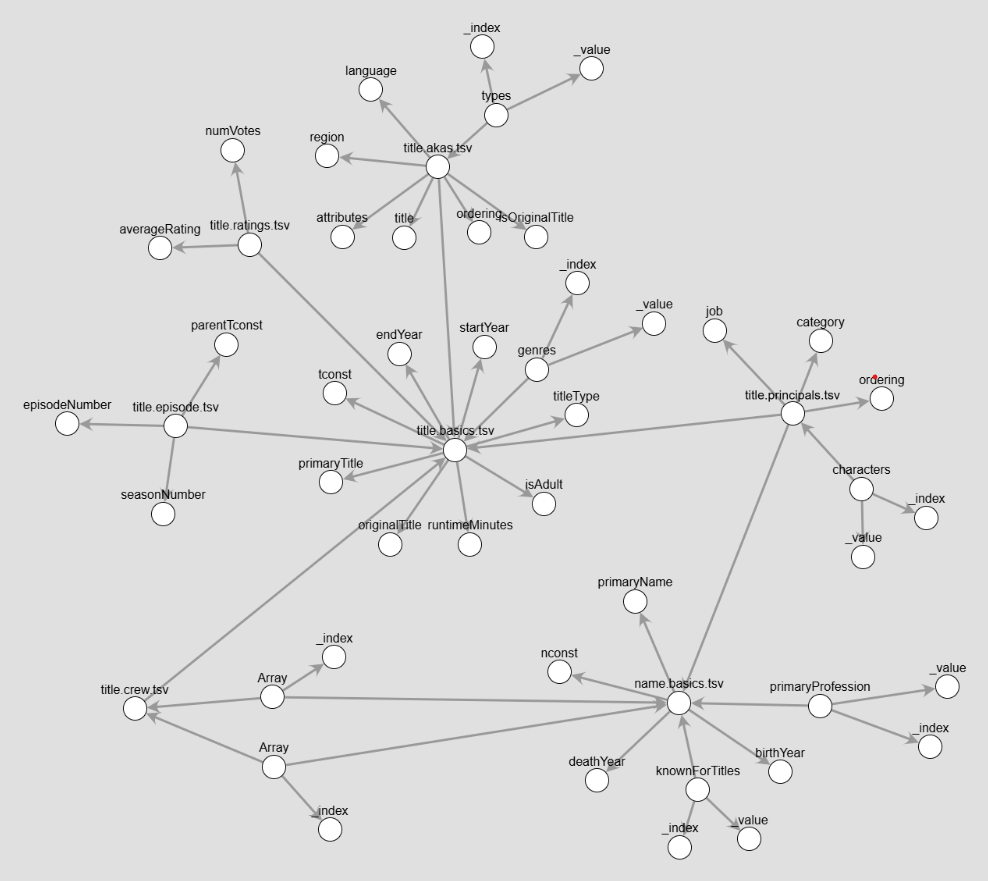
It is structured in TSV format including the following files:
name.basics.tsvwith information about individuals in the industrytitle.akas.tsvwith alternative title for movies and TV showstitle.basics.tsvwith fundamental details about titlestitle.crewwith lists of directors and writers for each titletitle.episode.tsvwith details for episodes of TV seriestitle.principals.tsvwith principal cast and crew for each titletitle.ratings.tsvwith user ratings for titles
| Entity | Data Link | Mapping |
|---|---|---|
| Name.basics | ||
| Title.akas | ||
| Title.basics | ||
| Title.crew | ||
| Title.episode | ||
| Title.principals | ||
| Title.ratings |
The title.basics table, which contains information about movies, TV shows, and other titles, is enriched by embedding additional data from the title.akas table. The title.akas table provides alternative titles for the same content, often specific to regions or languages. By embedding this data directly into each title’s JSON representation, the result is a unified, self-contained dataset where each title includes its own set of alternative titles.
Transforming the original TSV files into JSON with embedded data offers several benefits. Firstly, by embedding the alternative titles directly into each title from title.basics, the resulting JSON structure becomes self-contained - all information about a title is available in one place.Secondly, JSON is human-readable and easier to work with compared to TSV files, especially when dealing with hierarchical or nested data. And finally, the original TSV files separate title.basics and title.akas into different datasets, which can lead to redundant processing steps to combine them during analysis. JSON embedding simplifies this by consolidating the data at the storage stage.
| Entity | Output Mapping |
|---|---|
| Title.basics |
Generated File:
The title.crew data, which originally combined both directors and writers into a single file, is split into two separate CSV files. This separation ensures that each CSV file serves a more focused and specific purpose.
Having separate files allows users to work directly with the subset of data they need, reducing the preprocessing steps required to extract relevant information.
Currently, the tool can perform this splitting operation, but the process is somewhat inefficient. The tool duplicates the entire title.crew data and then removes directors from one file and writers from the other. While this method achieves the desired result, it is not optimal in terms of processing efficiency. To address this limitation, we plan to implement conditional mapping, a feature that will allow selective processing of data based on specific conditions. This feature is part of our planned future work and will make operations like this significantly faster and more efficient.
| Entity | Output Mapping |
|---|---|
| Title.crew.writers | |
| Title.crew.directors |
Generated Files: